
![[Howto] Create your own cloud gaming server to stream games to Fedora](https://liquidat.files.wordpress.com/2020/06/alien-226245_1920.jpg?w=1200)

A few months back I wanted to give a game a try which only runs on Windows and requires a dedicated GPU. Since I have neither of those, a decided to set up my own Windows cloud gaming server to stream the game to my Linux machine.
Dozens of years ago there was one game I played day and night. For weeks, months, maybe even years. Till today I can still remember the distinct soundtrack which makes the hair stand up on the back of my neck: UFO: Enemy Unknown. I loved the game! A few years ago I also played one of the open source games inspired by UFO quite some time, UFO: AI. That was fun.
Sequels to the original game were released, two over the last couple of years. But they never really were an option since they required Windows (or so I thought) and above all, time. However, few months ago I first realized that one of the sequels, XCOM: Enemy Unknown, was available for Android. Since I have a brand new flagship Android tablet I gave it a shot – and it was great! But since the Android version was seriously limited, I played it again on Linux. That barely worked with my limited Intel GPU. But it was playable, and I had fun.
I was infected with the urge to play the game more – and when a thid sequel was announced, I at least wanted to play the second one, XCOM 2. But how? My GPU was too limited and eGPUs are expensive and often involve a lot of hassle – even if I would be willing to buy a Windows license. So I searched if cloud gaming could do the trick.
Cloud Gaming Services
The idea of cloud gaming is that heavy machines in the data center do the rendering, and the client machine only displays the end result. That shifts the burden of the powerful GPU towards the data center, and the client only needs to have simple graphics to show a stream of images. This does however require a rather responsive broad band connection between the client and the data center.
This principle is not new, but got new attention recently when Google announced their cloud gaming offer Stadia. I checked if any cloud gaming services offered my game of choice – and was available on Linux. Unfortunately, the results were disappointing:
- Stadia: no XCOM2,
noLinux client via Chrome Browser (thanks to zesoup) - GeForce Now: no XCOM2, no Linux client
- Playstation Now: XCOM2 available, but no Linux client
- Vortex: no XCOM2, no Linux client
Some of the above can be used on Linux with the help of Lutris, which uses Wine in the background. But for me that would only count as a last resort. I was not that desperate yet.
However, not all was lost yet: some services are not tied to a certain game catalog, but instead offer a generic server and client onto which you can install your games. The research results were first promising: shadow.tech offers machines for just that and a working Linux client! However, they are not available at my place.
The solution: Parsec
So with all ready-to-consume options out of the picture, I was almost willing to give up (or give Lutris and Playstation Now a chance, or even buy a eGPU). But then I stumbled upon something interesting: Parsec, a client for interactive game streaming.
Parsec is a high performance, low latency 60 FPS remote access product connecting you to your computer from anywhere.
Parsec features
That itself didn’t solve my problem. But it opened a window to a new solution: in the past, the company offered cloud hosted game servers on their own. Players could connect to it with their Parsec client and play games on them together – or on their own. The Parsec promise is that their client is fast enough for a reasonable good experience.
The server offer was canceled some time ago – but there was no one stopping me launching my own server and connect the Parsec client to it. And that is what I did. Read on to learn how to do that yourself.
Step 1: Getting a Windows cloud server with a reasonable GPU
What is needed is a cloud hosted Windows machine with a reasonable GPU. In best case the data center hosting the machine should not be on the other side of the planet. AWS, Azure, GCP and other have such offers. But there is even a better route: during my research I found Paperspace, a company specialized on providing access to GPU or AI cloud platforms. That is perfect for this use case!
Paperspace does not really advertise their support for gaming platforms. But after I signed up and looked what was needed to create my first cloud server I found a Parsec template:

That makes the entire process very easy!
- Sign up with Paperspace, get billing sorted out (yes, this stuff costs money)
- Get to Core -> Compute -> Machines, create a new machine
- From Public Templates, get the Parsec cloud gaming template
- Pick the right size for your games; for me a P4000 was enough.
- Make sure to add a public IP and enough storage. Many today’s games easily consume dozens of GB
- Set the auto-shutdown timer. No need to waste money.
- Start the machine.
And that’s it already. Once the machine starts, you will notice a Parsec icon on the home screen. Time to get that working.
Step 2: Get Parsec
Parsec has clients for Linux based operating systems such as Ubuntu and Raspberry. There is even an AppImage or a Snap – unfortunately not a Flatpak yet. Update: there is now even a Flatpak package available! Thanks Sheogorath for the hint!
And if you are not willing to use Flatpak, AppImage or Snap for whatever reason, you can download the Ubuntu deb and create a RPM out of it. There is even a handy script for that. Any way, get it installed.
Sign up to Parsec, start the client, log in, and you are almost there:

Step 3: Play
After Parsec is all set, just start the cloud server, start Parsec there (maybe log in to your Parsec account), connect to the session on your client – and you are good to go: You can start playing!
For a first test I just watched some Youtube videos and was surprised by the quality. Next I logged in to my Steam account, got my XCOM2 installed and played along happily!
Performance and user experience
But how good is the performance? Well, that depends mostly on one factor: network. Due to unfortunate circumstances I was “able” to test this setup with three very distinct networks in a short time frame:
- A rather slowish, unstable WiFi with a lot of jitter
- A LTE connection, provided to me via WiFi hotspot
- A top-notch, high performance mesh WiFi
When you have slow pings (everything below 25 ms) and/or a lot of jitter, I cannot recommend that you go this path. Otherwise it can be a serious option!
The first network I was on was horrible slow, and the experience was horrible. XCOM2 has basically permanent background music, and the constant interruptions in the music and audio sequences were in fact the worst for me.
The LTE based network was slightly better, but still far from a native feeling. I was able to get a good experience out of this and have fun, but that about was it.
However, the third option, WiFi on almost wired quality, was so good that in times I forgot that I was not playing the game natively. There was no visible lag, the graphics were crystal clear, the music was never interrupted, etc. I was impressed – and had great sessions that way!
I can only recommend to always keep an eye on the connection quality reported in the Parsec overlay:

As Parsec mentions:
At 60 frames per second, 1 frame is around 16ms. By combining decode, encode and network, you’ll have the amount of frames the client lags behind.
Parsec about lag latency
Having this in mind, the above screenshot shows a connection with an unfortunate lag, leading to a not-that-good experience.
Recap
If you don’t have the hardware and/or software to play your favorite game, cloud gaming can be a solution for your problem. And if there is no proper offering out there, it is possible to get this working on your own.
Running your own cloud gaming server is surprisingly easy and not too expensive. It does feel somewhat weird in the beginning especially if you usually only use clouds for your professional work. But it is a fun experience, and the results can be staggering – if your network is up for the job!
Featured image by Martin Str from Pixabay
![[Howto] Three commands to update Fedora](https://liquidat.files.wordpress.com/2019/06/spread-1776657_1920.jpg?w=1200)



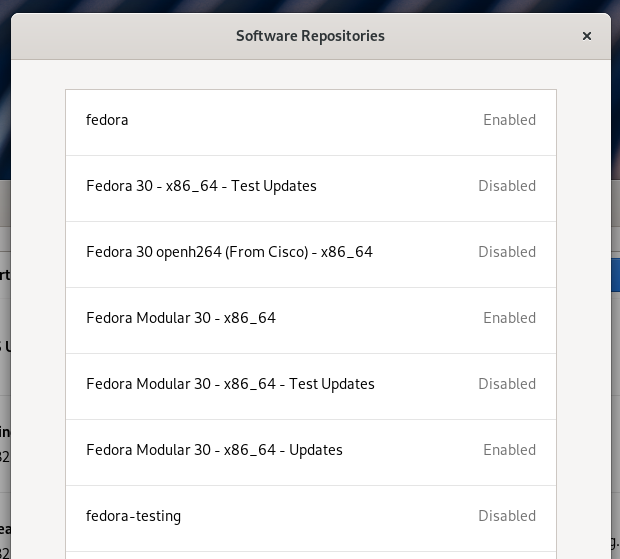

![[Howto] Rebasing Fedora Silverblue – even from Rawhide to Fedora 30](https://liquidat.files.wordpress.com/2019/05/gulf-1356004_1920.jpg?w=1200)
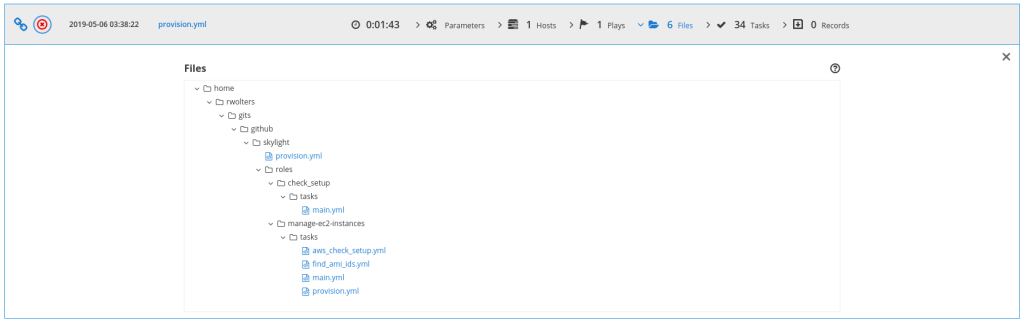
![[Howto] ara – making Ansible runs easier to read and understand](https://liquidat.files.wordpress.com/2019/05/ara-3601194_1920.jpg?w=1200)






![[Howto] Fix ldap “protocol error” in Gitea (and other Go based apps)](https://liquidat.files.wordpress.com/2019/03/tree-3822149_1920.jpg?w=1200)


