
![[Short Tip] Get all columns in a table](https://liquidat.files.wordpress.com/2024/03/pexels-photo-785080.jpeg?w=867)

When working with larger data structures in Nushell, there are often tables that are wider than the terminal has width, resulting in some columns truncated, indicated by the three dots .... But how can we expand the dots?
❯ ls -la
╭───┬──────────────────┬──────┬────────┬──────────┬─────╮
│ # │ name │ type │ target │ readonly │ ... │
├───┼──────────────────┼──────┼────────┼──────────┼─────┤
│ 0 │ 213-3123-43432.p │ file │ │ false │ ... │
│ │ df │ │ │ │ │
│ 1 │ barcode-picture. │ file │ │ false │ ... │
│ │ jpg │ │ │ │ │
│ 2 │ print-me-by-tomo │ file │ │ false │ ... │
│ │ rrow.pdf │ │ │ │ │
╰───┴──────────────────┴──────┴────────┴──────────┴─────╯The answer is simple, but surprisingly, not easily found. The “Working with tables” documentation of Nushell weirdly doesn’t tell, for example. The trick is to use the command columns to get a list of all column names:
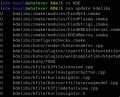
❯ ls -la|columns
╭────┬───────────╮
│ 0 │ name │
│ 1 │ type │
│ 2 │ target │
│ 3 │ readonly │
│ 4 │ mode │
│ 5 │ num_links │
│ 6 │ inode │
│ 7 │ user │
│ 8 │ group │
│ 9 │ size │
│ 10 │ created │
│ 11 │ accessed │
│ 12 │ modified │
╰────┴───────────╯And once you know that command, you can easily find the corresponding Nushell documentation: nushell.sh/commands/docs/columns.html
![[Short Tip] Processing line by line in a loop in Nushell](https://liquidat.files.wordpress.com/2024/03/pexels-photo-315791.jpeg?w=1200)
![[Short Tip] Using a Python virtual environment in Nushell](https://liquidat.files.wordpress.com/2023/09/pexels-photo-8245039.jpeg?w=868)
![[Short Tip] Plot live-data in Linux terminal](https://liquidat.files.wordpress.com/2022/05/screenshot-from-2022-05-17-22-05-34.png?w=1200)

![[Short Tip] Accessing tabular nushell output for non-nushell commands](https://liquidat.files.wordpress.com/2021/10/pexels-photo-3650427.jpeg?w=1200)
